AI Agent memory management: the architecture of memory & context
Agent Memory Management is the architectural system that allows an AI agent to maintain an evolving understanding of a task, the user, and its own actions
John Daniel Corporate finance, Mathematics, GenAI Verified By Expert
Published: August 16, 2025 | Updated: July 16, 2025
What is Agent Memory and Why is it More Than a Database?
Agent Memory Management is the architectural system that allows an AI agent to maintain an evolving understanding of a task, the user, and its own actions over time. This system enables an agent to store, retrieve, and utilize information from past interactions to inform its future decisions. It is the core component that separates a simple, one-shot AI tool from a truly persistent and autonomous collaborator.
Memory Gives AI Persistence: Agent memory is the external system that solves the inherent “amnesia” of AI models, enabling them to handle complex, multi-step tasks.
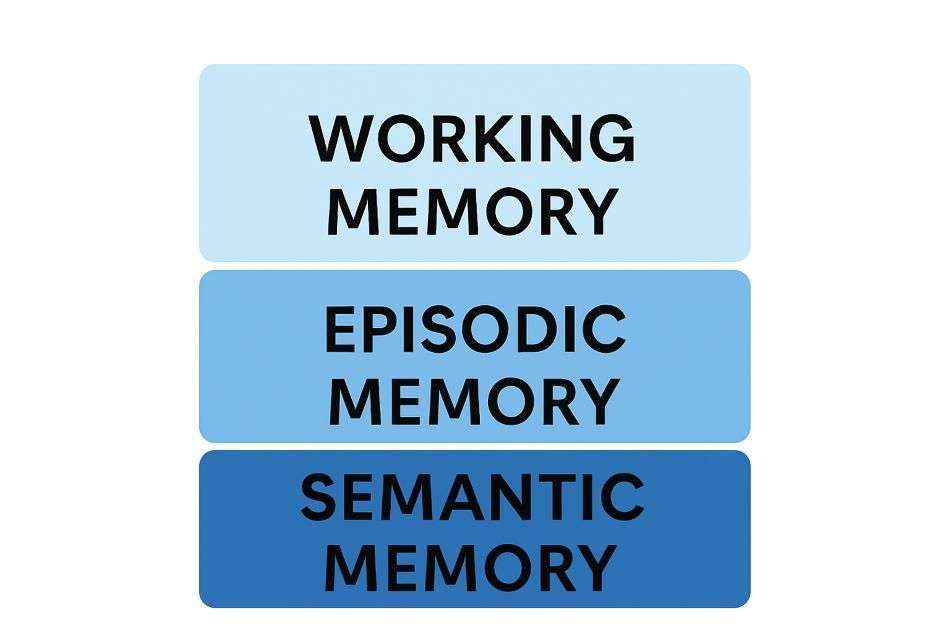
It’s a Three-Layer System: Memory is architected in three layers: short-term “Working Memory,” conversational “Episodic Memory,” and a permanent “Semantic Memory” (knowledge base).
RAG is the Core Process: Agents use Retrieval-Augmented Generation (RAG) to pull knowledge from long-term memory into their immediate context before acting.
Good Data Structure is Key: The quality of the long-term knowledge base depends on smart data practices like “chunking” large documents and adding metadata.
Maintenance and Security are Crucial: To work effectively, an agent’s memory must be continuously updated with high-quality information and secured to protect sensitive data.
This sophisticated system is necessary to solve a core limitation of the foundational models that power AI. The goal of effective agent memory management is to achieve AI agent persistence and a coherent autonomous AI state, transforming a forgetful machine into a reliable digital worker.
Foundational models like GPT-4 are inherently stateless. This “digital amnesia” means they have no built-in memory of past interactions; each new request is treated as a completely fresh start. This makes it impossible for them to perform any complex, multi-step task without an external memory system.
Agent memory management provides the solution. It is the architecture that allows an agent to maintain continuity, recall previous instructions, and learn from the results of its actions. This system is the difference between a simple calculator and a genuine collaborator that can manage a project over hours, days, or even weeks.
What is the Modern Architecture of an AI Agent’s Memory?
So, do ai agents has memory? Yes, but it is not a single entity. A modern agent’s memory is a sophisticated, multi-layered architecture designed to balance speed, cost, and capacity. Understanding these layers is key to understanding how do AI agents remember?
Layer 1: Working Memory (The Context Window)
What is Working Memory in an AI Agent? Working memory in an AI agent is its immediate, temporary “consciousness” used for the current step of a task. It is implemented using the AI model’s limited context window and holds the information the agent is actively thinking about.
What is the Function of Working Memory? The function of working memory is to provide the AI model with instant access to the most immediate context needed to make a decision or generate a response.
What is the Limitation of Working Memory? The primary limitation of working memory its the finite size and high operational cost. Because the entire context window is sent with each request, a large working memory is expensive and can cause the agent to “forget” the earliest parts of a long interaction as new information is added.
Layer 2: Episodic Memory (The Conversation Buffer)
What is Episodic Memory for an AI Agent? Episodic memory is an agent’s record of the turn-by-turn history of a specific conversation or task. Its purpose is to provide a coherent intelligent agent history so the agent can understand what has already been said and done.
How is Episodic Memory Managed? Episodic memory is managed through summarization. To avoid overflowing the limited working memory, an agent can be programmed to periodically condense older parts of the conversation into a shorter summary, preserving key AI agent context while saving space. This is a common practice detailed in frameworks like LangChain.
Layer 3: Semantic Memory (The Knowledge Base)
What is Semantic Memory for an AI Agent? Semantic memory is an agent’s permanent, searchable library of external facts, documents, and user preferences. In an agentic context, this is what is commonly referred to as a knowledge base.
What are Embeddings? Embeddings are numerical representations (vectors) of text or other data. They are used to capture the semantic meaning of content, allowing AI systems to understand and compare information based on conceptual relevance, not just matching keywords.
What is a Vector Database? A vector database is a specialized database designed to store and search these numerical embeddings. Its primary function is to allow for incredibly fast and scalable similarity searches, enabling an agent to find the most relevant information from its vast knowledge base in real-time.
When building an agent’s semantic memory, the choice of vector database is a critical architectural decision.
Pinecone: A fully managed, high-performance solution designed for enterprise-scale applications where speed and reliability are paramount.
Weaviate: An open-source vector database known for its strong hybrid search capabilities and flexibility in deployment.
Chroma/FAISS: Open-source libraries that are excellent for smaller projects, research, or local development where you want maximum control over the infrastructure.
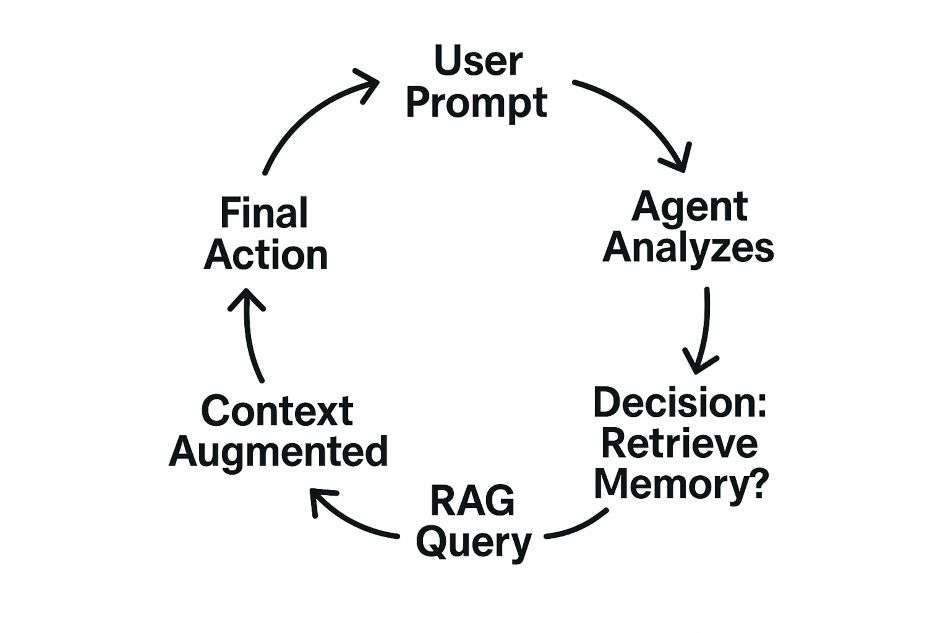
How Does an Agent Use its Memory? The RAG Process Explained
An agent doesn’t passively access memory; it actively retrieves it as part of a reasoning process.
What is RAG? Retrieval-Augmented Generation is the core process agents use to pull relevant information from their long-term Semantic Memory (the knowledge base) into their short-term Working Memory before making a decision or generating a response. This process dramatically improves the accuracy and relevance of the agent’s output.
This cycle is the essence of agent memory management. The agent constantly evaluates if it has enough AI agent context in its working memory to proceed, or if it needs to trigger a RAG query to retrieve more information.
What Are the Best Practices for Building a High-Performance Knowledge Base?
The answer to “How to build a knowledge base for an AI agent?” lies in careful data structuring and smart retrieval strategies.
✅ Best Practice: Chunking. Never store large documents as a single entry. Break them into small, semantically complete paragraphs or sections. A good chunk should make sense on its own, providing focused context during retrieval.
✅ Best Practice: Rich Metadata. Attach descriptive labels to each chunk (source, date, author, topic_tag). This is crucial for building a system that can perform accurate, filtered searches.
✅ Best Practice: Start with Hybrid Search. For the best results, combine semantic (meaning-based) search with traditional keyword search. This provides a powerful baseline that handles both conceptual queries and specific terms.
✅ Best Practice: Filter First, Then Search. Use your metadata to narrow the search space before performing the semantic search. According to best practices from vector database providers like Pinecone, this approach is faster, cheaper, and often yields more accurate results.
Consider an AI agent integrated with a CRM. It uses its memory layers to handle a customer query:
Working Memory: Holds the customer’s current question: “Does your top-tier plan integrate with Salesforce?”
Episodic Memory: The agent recalls the last five messages, noticing the customer previously asked about “enterprise features.”
Semantic Memory: The agent performs a RAG query on its knowledge base of product documentation, filtering for documents tagged with integration and enterprise_plan. It retrieves the specific chunk detailing the Salesforce integration.
Action: With all context assembled, the agent provides a precise, informed answer.
What Are Common Pitfalls in Implementing Agent Memory (And How to Avoid Them)?
Building a robust memory system requires avoiding common mistakes that can degrade an agent’s performance.
Mistake 1: Treating All Data Equally. Not all information is valuable. Storing trivial conversational fluff or redundant data in long-term memory creates “noise” that reduces retrieval accuracy. Implement a process to decide what is worth remembering.
Mistake 2: Neglecting Knowledge Base Maintenance. An intelligent agent history filled with outdated information is a liability. An agent with a stale memory will provide incorrect answers. Implement a process to periodically update or expire old data to maintain the integrity of the autonomous AI state.
Mistake 3: Ignoring Security and Privacy. An agent’s memory can contain sensitive personal or corporate data. This AI agent persistence makes the memory system a security target. Implementing strong encryption, access controls, and data anonymization is absolutely critical.
How Will Agent Memory Evolve in the Future?
The future of agent memory management is moving toward more dynamic and sophisticated systems.
The future lies in agents that can autonomously decide what information is important enough to commit to long-term memory. Instead of passively storing everything, the agent will learn to identify key facts, summaries, and user preferences, actively curating its own knowledge. This concept is explored in foundational AI research papers like “ReAct: Synergizing Reasoning and Acting in Language Models.“
The next frontier is developing a shared memory pool or “team blackboard” that a group of collaborating agents can access and update in real-time. This will allow for complex, coordinated actions where a team of specialized agents can work from a single source of truth, a key step in advanced agent memory management.
John Daniel Corporate finance, Mathematics, GenAI Verified By Expert
Meet John Daniell, who isn't your average number cruncher. He's a corporate strategy alchemist, his mind a crucible where complex mathematics melds with cutting-edge technology to forge growth strategies that ignite businesses.
MBA and ACA credentials are just the foundation: John's true playground is the frontier of emerging tech. Gen AI, 5G, Edge Computing – these are his tools, not slide rules. He's adept at navigating the intricacies of complex mathematical functions, not to solve equations, but to unravel the hidden patterns driving technology and markets.
His passion? Creating growth. Not just for companies, but for the minds around him.
Share This Article
JOIN OUR COMMUNITY
Receive the latest AI insights directly to your inbox.