Quản lý bộ nhớ tác nhân AI: kiến trúc của bộ nhớ và ngữ cảnh
Quản lý bộ nhớ tác nhân là hệ thống kiến trúc cho phép một tác nhân AI duy trì hiểu biết đang phát triển về một nhiệm vụ, người dùng và hành động của chính nó
John Daniel Corporate finance, Mathematics, GenAI Được Xác Nhận Bởi Chuyên Gia
Cập nhật: Tháng 9 3, 2025 | Cập nhật: Tháng 9 3, 2025
Bộ nhớ tác nhân là gì và tại sao nó nhiều hơn một cơ sở dữ liệu?
Quản lý bộ nhớ tác nhân là hệ thống kiến trúc cho phép một tác nhân AI duy trì hiểu biết đang phát triển về một nhiệm vụ, người dùng và hành động của chính mình theo thời gian. Hệ thống này cho phép một tác nhân lưu trữ, truy xuất và sử dụng thông tin từ các tương tác trước đó để thông báo các quyết định trong tương lai của mình. Nó là thành phần cốt lõi tách biệt một công cụ AI đơn giản, một lần với một cộng tác viên kiên định và tự chủ thực sự.
Bộ nhớ mang lại tính kiên định cho AI: Bộ nhớ tác nhân là hệ thống bên ngoài giải quyết vấn đề ‘mất trí nhớ’ vốn có của các mô hình AI, cho phép chúng xử lý các nhiệm vụ phức tạp, nhiều bước.
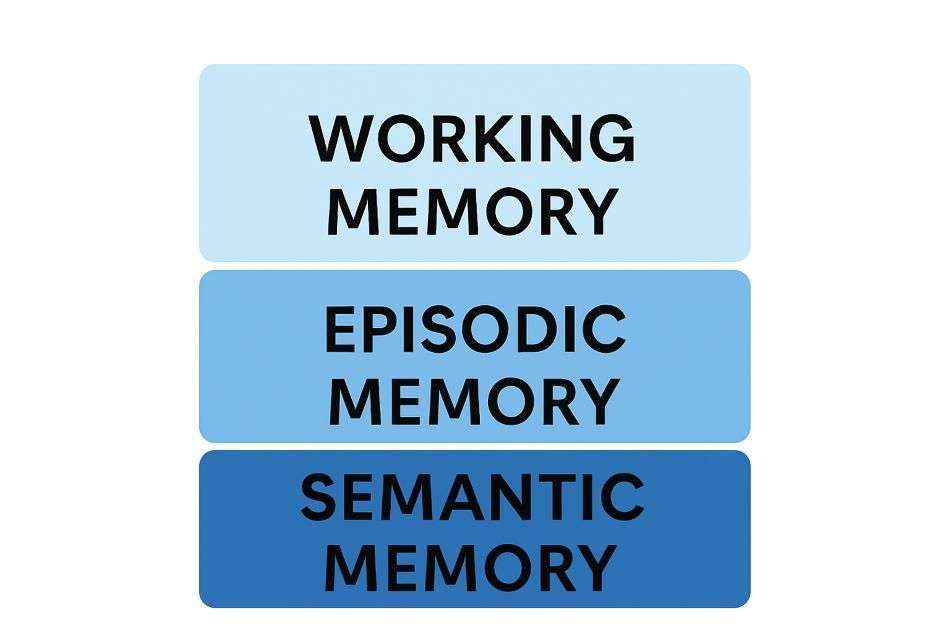
Đây là hệ thống ba lớp: Bộ nhớ được kiến trúc thành ba lớp: ‘Bộ nhớ làm việc’ ngắn hạn, ‘Bộ nhớ tập đoạn’ hội thoại, và ‘Bộ nhớ ngữ nghĩa’ lâu dài (cơ sở kiến thức).
RAG là quy trình cốt lõi: Các tác nhân sử dụng Tạo thế hệ tăng cường lấy thông tin (RAG) để lấy kiến thức từ bộ nhớ dài hạn vào ngữ cảnh ngay lập tức của chúng trước khi hành động.
Cấu trúc dữ liệu tốt là chìa khóa: Chất lượng của cơ sở kiến thức dài hạn phụ thuộc vào các thực tiễn dữ liệu thông minh như ‘chia nhỏ’ các tài liệu lớn và thêm siêu dữ liệu.
Duy trì và Bảo mật là Quan trọng: Để hoạt động hiệu quả, trí nhớ của một đại lý phải được cập nhật liên tục với thông tin chất lượng cao và được bảo vệ để bảo mật dữ liệu nhạy cảm.
Hệ thống phức tạp này là cần thiết để giải quyết một hạn chế cốt lõi của các mô hình nền tảng tạo ra AI. Mục tiêu của việc quản lý trí nhớ đại lý hiệu quả là đạt được sự bền vững của đại lý AI và một trạng thái AI tự động mạch lạc, biến một máy móc quên lãng thành một nhân viên kỹ thuật số đáng tin cậy.
Các mô hình nền tảng như GPT-4 vốn dĩ không có trạng thái. Sự ‘mất trí nhớ kỹ thuật số’ này có nghĩa là chúng không có trí nhớ tích hợp về các tương tác trước đây; mỗi yêu cầu mới được coi là một khởi đầu hoàn toàn mới. Điều này khiến chúng không thể thực hiện bất kỳ nhiệm vụ phức tạp, nhiều bước nào mà không có một hệ thống trí nhớ bên ngoài.
Quản lý trí nhớ đại lý cung cấp giải pháp. Đây là kiến trúc cho phép một đại lý duy trì sự liên tục, ghi nhớ các chỉ dẫn trước đó và học hỏi từ kết quả của các hành động của mình. Hệ thống này là sự khác biệt giữa một máy tính đơn giản và một cộng tác viên thực sự có thể quản lý một dự án trong nhiều giờ, ngày, hoặc thậm chí nhiều tuần.
Kiến trúc Hiện đại của Trí nhớ AI là gì?
Vậy, các đại lý AI có trí nhớ không? Có, nhưng nó không phải là một thực thể đơn lẻ. Trí nhớ của một đại diện hiện đại là một kiến trúc phức tạp, nhiều lớp được thiết kế để cân bằng tốc độ, chi phí và dung lượng. Hiểu về những lớp này là chìa khóa để hiểu cách AI ghi nhớ như thế nào?
Lớp 1: Trí nhớ Hoạt động (Cửa sổ Ngữ cảnh)
Trí nhớ Hoạt động trong AI là gì? Trí nhớ hoạt động trong một đại lý AI là ‘ý thức’ tạm thời, ngay lập tức của nó được sử dụng cho bước hiện tại của một nhiệm vụ. Nó được triển khai bằng cách sử dụng cửa sổ ngữ cảnh hạn chế của mô hình AI và giữ thông tin mà đại lý đang nghĩ đến tích cực.
Chức năng của Trí nhớ Làm việc (Working Memory) là gì? Chức năng của trí nhớ làm việc là cung cấp cho mô hình AI khả năng truy cập tức thời vào ngữ cảnh gần nhất cần thiết để đưa ra quyết định hoặc tạo ra phản hồi.
Giới hạn của Trí nhớ Làm việc là gì? Giới hạn chính của trí nhớ làm việc là kích thước hữu hạn và chi phí hoạt động cao. Vì toàn bộ cửa sổ ngữ cảnh được gửi đi với mỗi yêu cầu, nên trí nhớ làm việc lớn sẽ đắt đỏ và có thể khiến tác nhân ‘quên’ phần đầu của một cuộc tương tác dài khi có thêm thông tin mới.
Lớp 2: Trí nhớ Tập trung (Bộ đệm Hội thoại)
Trí nhớ Tập trung đối với tác nhân AI là gì? Trí nhớ tập trung là một bản ghi của tác nhân về lịch sử quay vòng từng lượt của một cuộc hội thoại hoặc nhiệm vụ cụ thể. Mục đích của nó là cung cấp một lịch sử tác nhân thông minh liên tục để tác nhân có thể hiểu được những gì đã được nói và thực hiện.
Làm thế nào để Quản lý Trí nhớ Tập trung? Trí nhớ tập trung được quản lý thông qua việc tóm tắt. Để tránh tràn bộ nhớ làm việc hạn chế, một tác nhân có thể được lập trình để định kỳ cô đọng các phần cũ hơn của cuộc đối thoại thành một bản tóm tắt ngắn hơn, bảo toàn ngữ cảnh tác nhân AI quan trọng trong khi tiết kiệm không gian. Đây là một thực hành phổ biến được chi tiết trong các khuôn khổ như LangChain.
Lớp 3: Trí nhớ Ngữ nghĩa (Cơ sở Kiến thức)
Trí nhớ Ngữ nghĩa đối với tác nhân AI là gì? Trí nhớ ngữ nghĩa là thư viện tìm kiếm vĩnh viễn của tác nhân về các sự kiện bên ngoài, tài liệu và sở thích người dùng. Trong ngữ cảnh tác nhân, đây là điều thường được gọi là cơ sở kiến thức.
Nhúng là gì? Nhúng là cách biểu diễn số học (vector) của văn bản hoặc dữ liệu khác. Chúng được sử dụng để nắm bắt ý nghĩa ngữ nghĩa của nội dung, cho phép hệ thống AI hiểu và so sánh thông tin dựa trên sự tương quan khái niệm, không chỉ là việc đối chiếu từ khóa.
Cơ sở dữ liệu Vector là gì? Một cơ sở dữ liệu vector là một cơ sở dữ liệu chuyên biệt được thiết kế để lưu trữ và tìm kiếm các biểu diễn số này. Chức năng chính của nó là cho phép thực hiện các tìm kiếm tương tự nhanh chóng và có khả năng mở rộng cao, giúp cho một tác nhân có thể tìm thấy thông tin liên quan nhất từ cơ sở kiến thức khổng lồ của mình trong thời gian thực.
Khi xây dựng bộ nhớ ngữ nghĩa của một tác nhân, lựa chọn cơ sở dữ liệu vector là một quyết định kiến trúc quan trọng.
Pinecone: Một giải pháp hoàn toàn được quản lý, hiệu suất cao được thiết kế cho các ứng dụng quy mô doanh nghiệp, nơi mà tốc độ và độ tin cậy là quan trọng.
Weaviate: Một cơ sở dữ liệu vector mã nguồn mở nổi tiếng với khả năng tìm kiếm hybrid mạnh mẽ và tính linh hoạt trong việc triển khai.
Chroma/FAISS: Các thư viện mã nguồn mở tuyệt vời cho các dự án nhỏ hơn, nghiên cứu hoặc phát triển cục bộ nơi bạn muốn có sự kiểm soát tối đa đối với cơ sở hạ tầng.
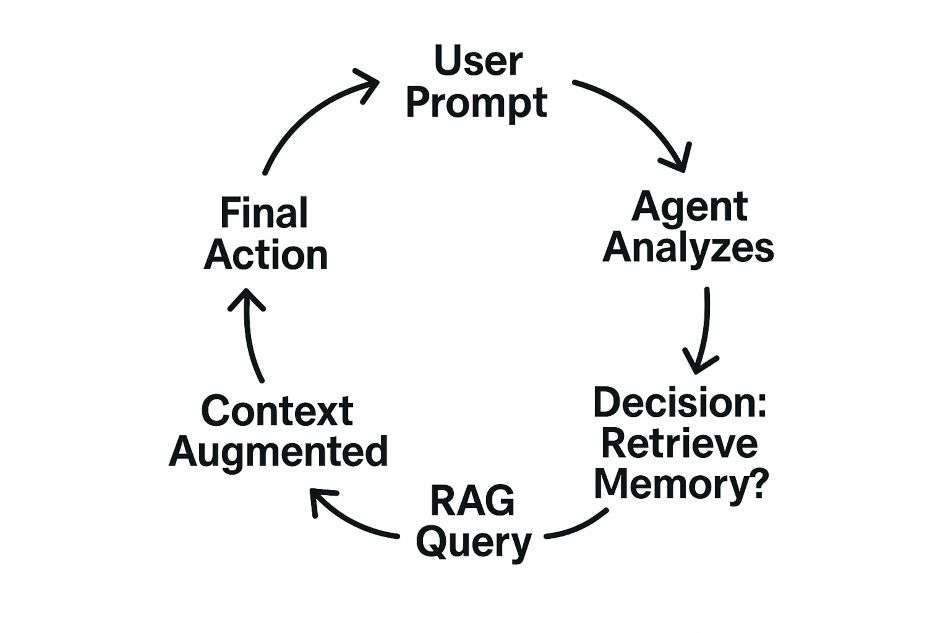
Tác nhân sử dụng bộ nhớ của nó như thế nào? Quá trình RAG được giải thích
Một tác nhân không truy cập bộ nhớ một cách thụ động; nó chủ động truy xuất như là một phần của quá trình lập luận.
RAG là gì? Retrieval-Augmented Generation là quá trình cốt lõi mà các tác nhân sử dụng để lấy thông tin liên quan từ Bộ nhớ Ngữ nghĩa dài hạn (tức là cơ sở kiến thức) vào Bộ nhớ Làm việc ngắn hạn trước khi ra quyết định hoặc tạo phản hồi. Quá trình này cải thiện đáng kể độ chính xác và sự liên quan của kết quả của tác nhân.
Chu kỳ này là bản chất của quản lý bộ nhớ tác nhân. Tác nhân liên tục đánh giá liệu nó có đủ ngữ cảnh của tác nhân AI trong bộ nhớ làm việc của mình để tiếp tục hay không, hoặc nếu cần kích hoạt truy vấn RAG để truy xuất thêm thông tin.
Các thực hành tốt nhất để xây dựng một cơ sở kiến thức hiệu suất cao là gì?
Câu trả lời cho ‘Làm thế nào để xây dựng một cơ sở kiến thức cho một tác nhân AI?‘ nằm ở việc cấu trúc dữ liệu cẩn thận và các chiến lược truy xuất thông minh.
✅ Thực hành tốt nhất: Chia nhỏ. Không bao giờ lưu trữ các tài liệu lớn dưới dạng một mục duy nhất. Hãy chia chúng thành các đoạn văn hoặc phần nhỏ, hoàn chỉnh về mặt ngữ nghĩa. Một đoạn văn tốt nên có ý nghĩa độc lập, cung cấp ngữ cảnh tập trung trong quá trình truy xuất.
✅ Thực hành tốt nhất: Siêu dữ liệu phong phú. Gắn các nhãn mô tả cho mỗi đoạn văn (nguồn, ngày tháng, tác giả, thẻ chủ đề). Đây là điều cần thiết để xây dựng một hệ thống có thể thực hiện các tìm kiếm chính xác, có lọc.
✅ Thực hành tốt nhất: Bắt đầu với tìm kiếm lai. Để có kết quả tốt nhất, kết hợp tìm kiếm ngữ nghĩa (dựa trên ý nghĩa) với tìm kiếm từ khóa truyền thống. Điều này tạo nên một nền tảng mạnh mẽ xử lý cả các truy vấn khái niệm và các từ cụ thể.
✅ Thực hành tốt nhất: Lọc trước, sau đó tìm kiếm. Sử dụng siêu dữ liệu của bạn để thu hẹp không gian tìm kiếm trước khi thực hiện tìm kiếm ngữ nghĩa. Theo các nhà cung cấp cơ sở dữ liệu vector như Pinecone, phương pháp này nhanh hơn, rẻ hơn và thường mang lại kết quả chính xác hơn.
Hãy xem xét một tác nhân AI tích hợp với CRM. Nó sử dụng các lớp bộ nhớ của mình để xử lý câu hỏi của khách hàng:
Bộ nhớ hoạt động: Giữ câu hỏi hiện tại của khách hàng: ‘Gói cao cấp của bạn có tích hợp với Salesforce không?’
Bộ nhớ tập truyện: Tác nhân nhớ lại năm tin nhắn cuối, nhận ra rằng khách hàng trước đó đã hỏi về ‘các chức năng doanh nghiệp.’
Bộ nhớ ngữ nghĩa: Tác nhân thực hiện truy vấn RAG trên cơ sở tri thức của tài liệu sản phẩm, lọc các tài liệu được gắn thẻ tích hợp và kế hoạch_doanh nghiệp. Nó truy xuất đoạn cụ thể chi tiết về sự tích hợp Salesforce.
Hành động: Với tất cả bối cảnh đã được tập hợp, agent cung cấp một câu trả lời chính xác và thông thái.
Những Cạm Bẫy Thường Gặp Khi Triển Khai Bộ Nhớ Của Agent (Và Cách Tránh Chúng)?
Xây dựng một hệ thống bộ nhớ vững chắc yêu cầu tránh những sai lầm phổ biến có thể làm suy giảm hiệu suất của agent.
Sai lầm 1: Xem Tất Cả Dữ Liệu Như Nhau. Không phải tất cả thông tin đều có giá trị. Lưu trữ các thông tin tán gẫu vô nghĩa hoặc dữ liệu dư thừa trong bộ nhớ dài hạn tạo ra ‘nhiễu’ làm giảm độ chính xác khi truy xuất. Thực hiện một quy trình để quyết định điều gì đáng được ghi nhớ.
Sai lầm 2: Bỏ Qua Việc Bảo Trì Cơ Sở Tri Thức. Một lịch sử agent thông minh đầy những thông tin lỗi thời là một gánh nặng. Một agent với bộ nhớ cũ kĩ sẽ cung cấp những câu trả lời sai. Thực hiện một quy trình để định kỳ cập nhật hoặc loại bỏ dữ liệu cũ nhằm duy trì tính toàn vẹn của trạng thái AI tự trị.
Sai lầm 3: Bỏ Qua An Ninh và Sự Riêng Tư. Bộ nhớ của agent có thể chứa dữ liệu cá nhân hoặc dữ liệu doanh nghiệp nhạy cảm. Sự kiên trì của agent AI này làm cho hệ thống bộ nhớ trở thành mục tiêu an ninh. Việc triển khai mã hóa mạnh mẽ, kiểm soát truy cập và ẩn danh dữ liệu là cực kỳ quan trọng.
Bộ Nhớ Của Agent Sẽ Phát Triển Thế Nào Trong Tương Lai?
Tương lai của quản lý bộ nhớ agent đang tiến tới các hệ thống linh hoạt và tinh vi hơn.
Tương lai nằm ở những agent có thể tự động quyết định thông tin nào quan trọng đủ để được ghi nhớ dài hạn. Thay vì bị động lưu trữ mọi thứ, agent sẽ học cách xác định các thông tin chính, tóm tắt, và sở thích của người dùng, chủ động quản lý kiến thức của chính mình. Khái niệm này được khám phá trong các bài nghiên cứu nền tảng AI như ‘ReAct: Synergizing Reasoning and Acting in Language Models.‘
Biên giới tiếp theo là phát triển một bộ nhớ chung hoặc ‘bảng đen nhóm’ mà một nhóm các tác nhân hợp tác có thể truy cập và cập nhật theo thời gian thực. Điều này sẽ cho phép các hành động phức tạp và phối hợp, nơi một nhóm các tác nhân chuyên trách có thể làm việc từ một nguồn sự thật duy nhất, một bước quan trọng trong quản lý bộ nhớ tác nhân tiên tiến.
John Daniel Corporate finance, Mathematics, GenAI Được Xác Nhận Bởi Chuyên Gia
Meet John Daniell, who isn't your average number cruncher. He's a corporate strategy alchemist, his mind a crucible where complex mathematics melds with cutting-edge technology to forge growth strategies that ignite businesses.
MBA and ACA credentials are just the foundation: John's true playground is the frontier of emerging tech. Gen AI, 5G, Edge Computing – these are his tools, not slide rules. He's adept at navigating the intricacies of complex mathematical functions, not to solve equations, but to unravel the hidden patterns driving technology and markets.
His passion? Creating growth. Not just for companies, but for the minds around him.
Chia Sẻ Bài Viết
THAM GIA CỘNG ĐỒNG
Nhận thông tin mới nhất về AI trực tiếp vào hộp thư của bạn.