Gestión de memoria de agentes IA: la arquitectura de la memoria y el contexto
La gestión de la memoria de agentes es el sistema arquitectónico que permite a un agente de IA mantener una comprensión en evolución de una tarea, el usuario y sus propias acciones
John Daniel Corporate finance, Mathematics, GenAI Verificado por Experto
Publicado: septiembre 5, 2025 | Actualizado: septiembre 5, 2025
Gestión de memoria de agentes IA: ¿Por qué la memoria de un agente va más allá de una simple base de datos?
Gestión de memoria de agentes IA es el sistema arquitectónico que permite a un agente de IA mantener una comprensión en evolución de una tarea, el usuario y sus propias acciones a lo largo del tiempo. Este sistema permite a un agente almacenar, recuperar y utilizar información de interacciones pasadas para informar sus decisiones futuras. Es el componente central que separa una herramienta de IA sencilla y de uso único de un colaborador verdaderamente persistente y autónomo.
La memoria da persistencia a la IA: La memoria de agente es el sistema externo que resuelve la ‘amnesia’ inherente de los modelos de IA, permitiéndoles manejar tareas complejas y de múltiples pasos.
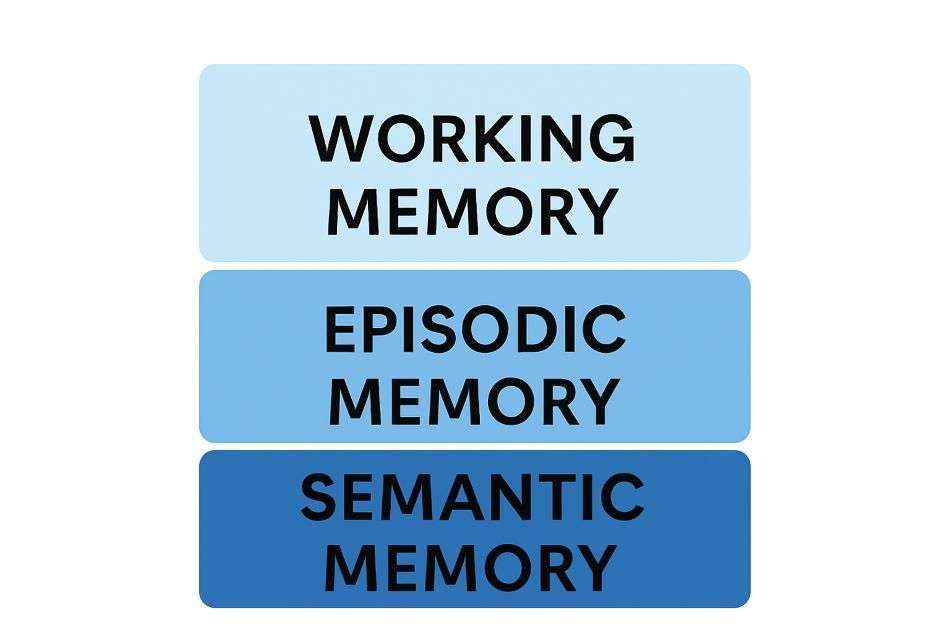
Es un sistema de tres capas: La memoria está diseñada en tres capas: ‘Memoria de Trabajo’ a corto plazo, ‘Memoria Episódica’ conversacional y ‘Memoria Semántica’ permanente (base de conocimiento).
RAG es el proceso central: Los agentes utilizan la Generación Aumentada por Recuperación (RAG) para extraer conocimiento de la memoria a largo plazo en su contexto inmediato antes de actuar.
Una buena estructura de datos es clave: La calidad de la base de conocimiento a largo plazo depende de prácticas de datos inteligentes como ‘dividir en partes’ grandes documentos y añadir metadatos.
Mantenimiento y Seguridad son Cruciales: Para trabajar de manera efectiva, la memoria de un agente debe actualizarse continuamente con información de alta calidad y asegurarse para proteger datos sensibles.
Este sistema sofisticado es necesario para resolver una limitación central de los modelos fundamentales que impulsan la IA. El objetivo de una gestión efectiva de la memoria del agente es lograr la persistencia del agente de IA y un estado de IA autónoma coherente, transformando una máquina olvidadiza en un trabajador digital confiable.
Los modelos fundamentales como GPT-4 son inherentemente sin estado. Esta ‘amnesia digital’ significa que no tienen memoria integrada de interacciones pasadas; cada nueva solicitud se trata como un comienzo completamente fresco. Esto hace imposible que realicen cualquier tarea compleja y de múltiples pasos sin un sistema de memoria externo.
La gestión de la memoria del agente proporciona la solución. Es la arquitectura que permite a un agente mantener la continuidad, recordar instrucciones previas y aprender de los resultados de sus acciones. Este sistema marca la diferencia entre una calculadora simple y un verdadero colaborador que puede gestionar un proyecto durante horas, días o incluso semanas.
¿Cuál es la Arquitectura Moderna de la Memoria de un Agente de IA?
Entonces, ¿los agentes de IA tienen memoria? Sí, pero no es una entidad única. La memoria de un agente moderno es una arquitectura sofisticada y de múltiples capas diseñada para equilibrar velocidad, costo y capacidad. Comprender estas capas es clave para entender ¿cómo recuerdan los agentes de IA?
Capa 1: Memoria de Trabajo (La Ventana de Contexto)
¿Qué es la Memoria de Trabajo en un Agente de IA? La memoria de trabajo en un agente de IA es su ‘consciencia’ inmediata y temporal utilizada para el paso actual de una tarea. Se implementa utilizando la ventana de contexto limitada del modelo de IA y contiene la información sobre la que el agente está pensando activamente.
¿Cuál es la función de la memoria de trabajo? La función de la memoria de trabajo es proporcionar al modelo de IA acceso instantáneo al contexto más inmediato necesario para tomar una decisión o generar una respuesta.
¿Cuál es la limitación de la memoria de trabajo? La principal limitación de la memoria de trabajo es su tamaño finito y alto costo operacional. Debido a que se envía la ventana de contexto completa con cada solicitud, una memoria de trabajo grande es costosa y puede causar que el agente ‘olvide’ las partes más iniciales de una interacción larga a medida que se añade nueva información.
Capa 2: Memoria episódica (El búfer de la conversación)
¿Qué es la memoria episódica para un agente de IA? La memoria episódica es el registro de un agente del historial turno a turno de una conversación o tarea específica. Su propósito es proporcionar una historia del agente inteligente coherente para que el agente pueda entender lo que ya se ha dicho y hecho.
¿Cómo se gestiona la memoria episódica? La memoria episódica se gestiona mediante la resumión. Para evitar sobrecargar la memoria de trabajo limitada, se puede programar a un agente para condensar periódicamente las partes más antiguas de la conversación en un resumen más corto, preservando el contexto del agente de IA clave mientras se ahorra espacio. Esta es una práctica común detallada en marcos como LangChain.
Capa 3: Memoria semántica (La base de conocimiento)
¿Qué es la memoria semántica para un agente de IA? La memoria semántica es una biblioteca permanente y buscable de un agente de hechos externos, documentos y preferencias del usuario. En un contexto agentico, esto es lo que comúnmente se denomina una base de conocimiento.
¿Qué son las incrustaciones? Las incrustaciones son representaciones numéricas (vectores) de texto u otros datos. Se utilizan para captar el significado semántico del contenido, permitiendo que los sistemas de IA entiendan y comparen la información basándose en la relevancia conceptual, no solo en la coincidencia de palabras clave.
¿Qué es una base de datos vectorial? Una base de datos vectorial es una base de datos especializada diseñada para almacenar y buscar estos embeddings numéricos. Su función principal es permitir búsquedas de similitud increíblemente rápidas y escalables, permitiendo a un agente encontrar la información más relevante de su amplia base de conocimiento en tiempo real.
Al construir la memoria semántica de un agente, la elección de la base de datos vectorial es una decisión arquitectónica crítica.
Pinecone: Una solución completamente gestionada y de alto rendimiento diseñada para aplicaciones a escala empresarial donde la velocidad y la confiabilidad son primordiales.
Weaviate: Una base de datos vectorial de código abierto conocida por sus fuertes capacidades de búsqueda híbrida y flexibilidad en el despliegue.
Chroma/FAISS: Bibliotecas de código abierto que son excelentes para proyectos más pequeños, investigación o desarrollo local donde se desea máximo control sobre la infraestructura.
¿Cómo utiliza un agente su memoria? El proceso RAG explicado
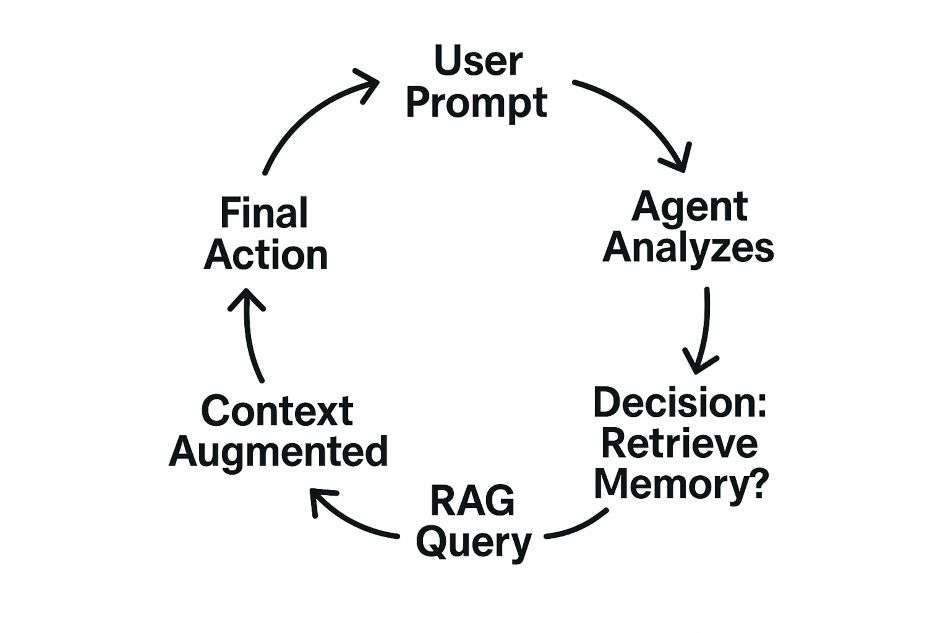
Un agente no accede a la memoria de manera pasiva; la recupera activamente como parte de un proceso de razonamiento.
¿Qué es RAG? La Generación Aumentada por Recuperación es el proceso principal que los agentes utilizan para extraer información relevante de su Memoria Semántica a largo plazo (la base de conocimiento) en su Memoria de Trabajo a corto plazo antes de tomar una decisión o generar una respuesta. Este proceso mejora drásticamente la precisión y la relevancia de la salida del agente.
Este ciclo es la esencia de la gestión de memoria del agente. El agente evalúa constantemente si tiene suficiente Contexto de agentes de IA en su memoria de trabajo para proceder, o si necesita activar una consulta RAG para recuperar más información.
¿Cuáles son las mejores prácticas para construir una base de conocimiento de alto rendimiento?
La respuesta a ‘¿Cómo construir una base de conocimiento para un agente de IA?‘ radica en una estructuración cuidadosa de los datos y en estrategias inteligentes de recuperación.
✅ Mejor práctica: Fragmentación. Nunca almacenes documentos grandes como una sola entrada. Divídelos en párrafos o secciones pequeñas y semánticamente completas. Un buen fragmento debe tener sentido por sí mismo, proporcionando un contexto enfocado durante la recuperación.
✅ Mejor práctica: Metadatos enriquecidos. Adjunta etiquetas descriptivas a cada fragmento (fuente, fecha, autor, tema_etiqueta). Esto es crucial para construir un sistema que pueda realizar búsquedas precisas y filtradas.
✅ Mejor práctica: Comienza con búsqueda híbrida. Para obtener los mejores resultados, combina la búsqueda semántica (basada en el significado) con la búsqueda tradicional por palabras clave. Esto proporciona una base poderosa que maneja tanto consultas conceptuales como términos específicos.
✅ Mejor práctica: Filtra primero, luego busca. Usa tus metadatos para reducir el espacio de búsqueda antes de realizar la búsqueda semántica. Según las mejores prácticas de proveedores de bases de datos vectoriales como Pinecone, este enfoque es más rápido, económico y a menudo produce resultados más precisos.
Considera un agente de IA integrado con un CRM. Utiliza sus capas de memoria para manejar una consulta del cliente:
Memoria de trabajo: Contiene la pregunta actual del cliente: ‘¿El plan de nivel superior se integra con Salesforce?’
Memoria episódica: El agente recuerda los últimos cinco mensajes, notando que el cliente preguntó previamente sobre ‘características empresariales.’
Memoria semántica: El agente realiza una consulta RAG en su base de conocimiento de documentación de productos, filtrando documentos etiquetados con integración y plan_empresarial. Recupera el fragmento específico que detalla la integración con Salesforce.
Acción: Con todo el contexto reunido, el agente proporciona una respuesta precisa e informada.
¿Cuáles son los errores comunes al implementar la memoria de un agente (y cómo evitarlos)?
Construir un sistema de memoria robusto requiere evitar errores comunes que pueden degradar el rendimiento de un agente.
Error 1: Tratar todos los datos por igual. No toda la información es valiosa. Almacenar información trivial o redundante en la memoria a largo plazo crea ‘ruido’ que reduce la precisión de la recuperación. Implementa un proceso para decidir qué vale la pena recordar.
Error 2: Descuidar el mantenimiento de la base de conocimiento. Una historia del agente inteligente llena de información obsoleta es un pasivo. Un agente con una memoria obsoleta proporcionará respuestas incorrectas. Implementa un proceso para actualizar o eliminar periódicamente los datos antiguos para mantener la integridad del estado de IA autónoma.
Error 3: Ignorar la seguridad y la privacidad. La memoria de un agente puede contener datos personales o corporativos sensibles. Esta persistencia del agente de IA convierte el sistema de memoria en un objetivo de seguridad. Implementar una fuerte encriptación, controles de acceso y anonimización de datos es absolutamente crítico.
¿Cómo evolucionará la memoria de los agentes en el futuro?
El futuro de la gestión de memoria de agentes se está moviendo hacia sistemas más dinámicos y sofisticados.
El futuro reside en agentes que puedan decidir autónomamente qué información es lo suficientemente importante para comprometerse con la memoria a largo plazo. En lugar de almacenar todo pasivamente, el agente aprenderá a identificar hechos clave, resúmenes y preferencias del usuario, seleccionando activamente su propio conocimiento. Este concepto se explora en artículos de investigación fundamentales de IA como ‘ReAct: Synergizing Reasoning and Acting in Language Models.‘
La próxima frontera es desarrollar un grupo de memoria compartida o ‘pizarra del equipo’ que un grupo de agentes colaboradores pueda acceder y actualizar en tiempo real. Esto permitirá acciones complejas y coordinadas donde un equipo de agentes especializados pueda trabajar desde una sola fuente de verdad, un paso clave en la gestión avanzada de la memoria de agentes.
John Daniel Corporate finance, Mathematics, GenAI Verificado por Experto
Meet John Daniell, who isn't your average number cruncher. He's a corporate strategy alchemist, his mind a crucible where complex mathematics melds with cutting-edge technology to forge growth strategies that ignite businesses.
MBA and ACA credentials are just the foundation: John's true playground is the frontier of emerging tech. Gen AI, 5G, Edge Computing – these are his tools, not slide rules. He's adept at navigating the intricacies of complex mathematical functions, not to solve equations, but to unravel the hidden patterns driving technology and markets.
His passion? Creating growth. Not just for companies, but for the minds around him.
Compartir Este Artículo
ÚNETE A NUESTRA COMUNIDAD
Recibe las últimas novedades de IA directamente en tu correo.